![[レポート]BUILD TOKYO ONLINE:Snowflakeの進化するデータパイプライン構築 -Apache Icebergのパイプライン組み込みやデータエンジニアリング機能のアップデート-](https://devio2024-media.developers.io/image/upload/f_auto,q_auto,w_3840/v1734409023/user-gen-eyecatch/lyxvtn3bp9opm76hlfal.png)
[レポート]BUILD TOKYO ONLINE:Snowflakeの進化するデータパイプライン構築 -Apache Icebergのパイプライン組み込みやデータエンジニアリング機能のアップデート-
2024.12.17
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
さがらです。
2024年12月17日に、Snowflakeの開発者向けのカンファレンスである「BUILD TOKYO ONLINE」が開催されました。
本記事はその中のセッション「Snowflakeの進化するデータパイプライン構築 -Apache Icebergのパイプライン組み込みやデータエンジニアリング機能のアップデート-」のレポート記事となります。
登壇者
Snowflake合同会社
セールスエンジニアリング統括本部
セールスエンジニア
深森 健志郎 氏
アジェンダ

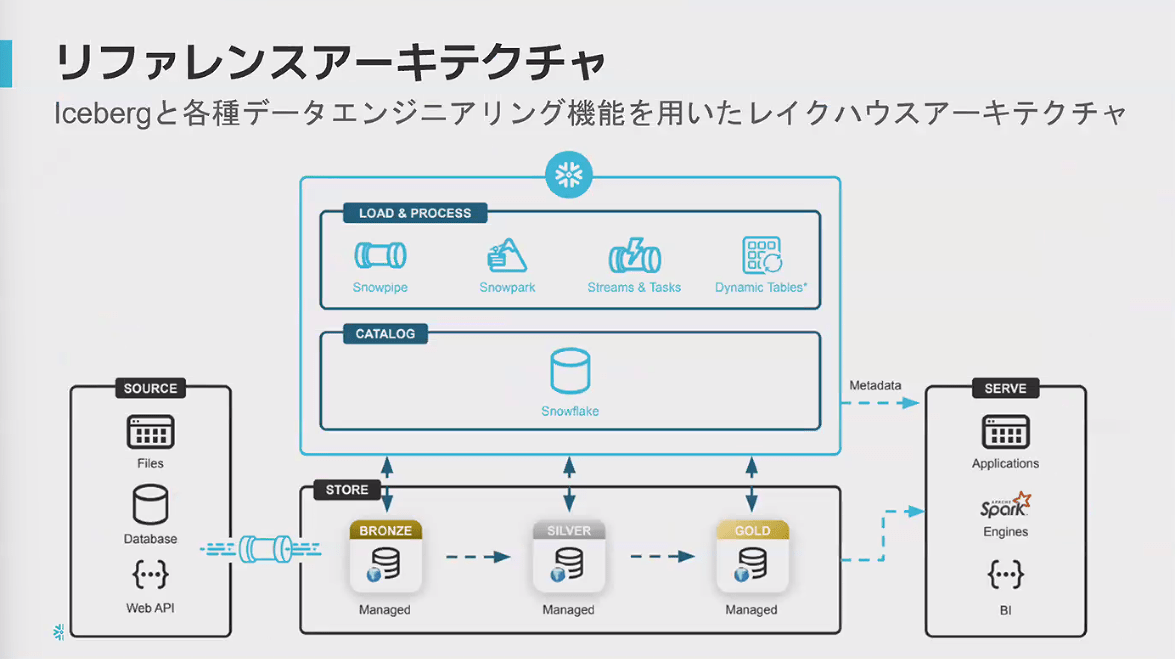
Apache Iceberg概要
- Netflixによって開発されて、現在はApache Foundationに寄贈されて開発されている
- 多様なクエリエンジンに対応
- ベンダーロックインを避けて信頼性やパフォーマンスの高いものを採用したい、という層が多いため特に注目されている

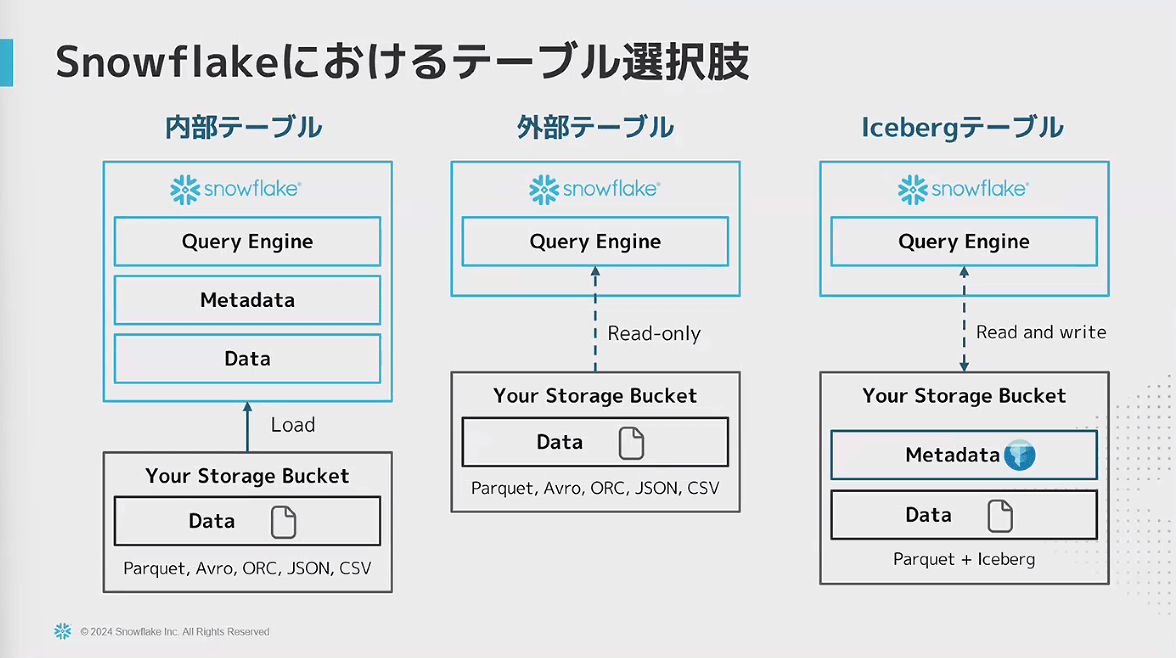
- Snowflakeにおけるテーブル選択肢の1つとして、Icebergテーブルがある
- Icebergテーブルは、内部テーブル・外部テーブル双方の課題をクリアしたテーブル
- Icebergはメタデータを保持することで、他のシステムからも参照できる
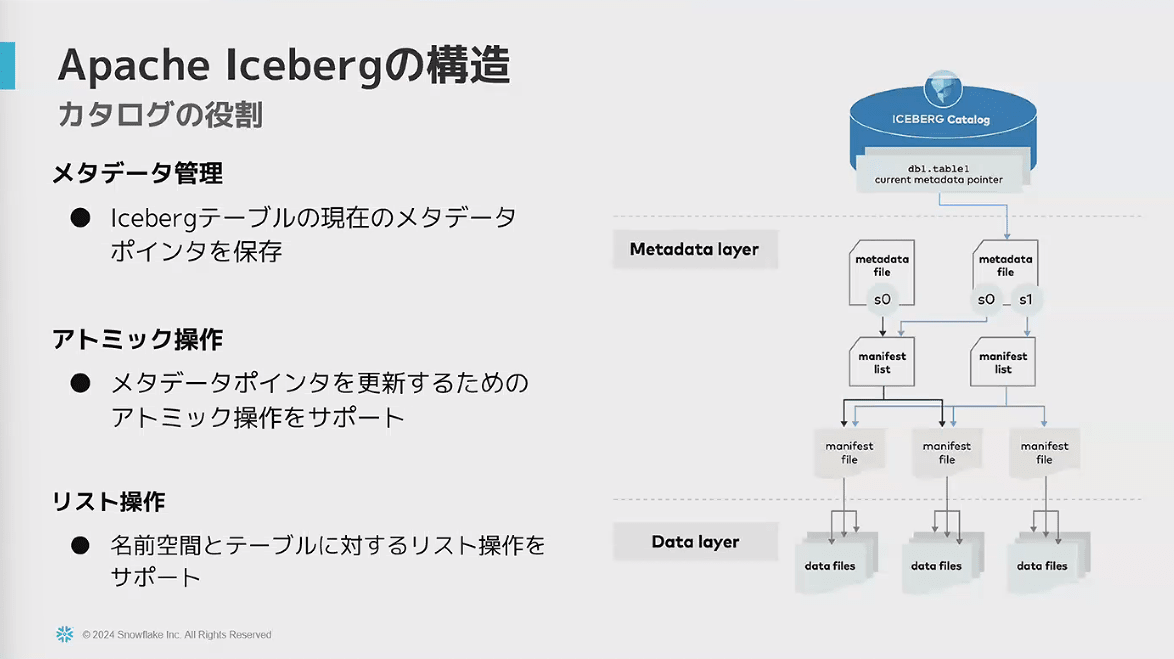
- Apache Icebergの構造
- カタログを参照して、メタデータが参照する最新のテーブルの状態を確認し、テーブルとして扱うことができる
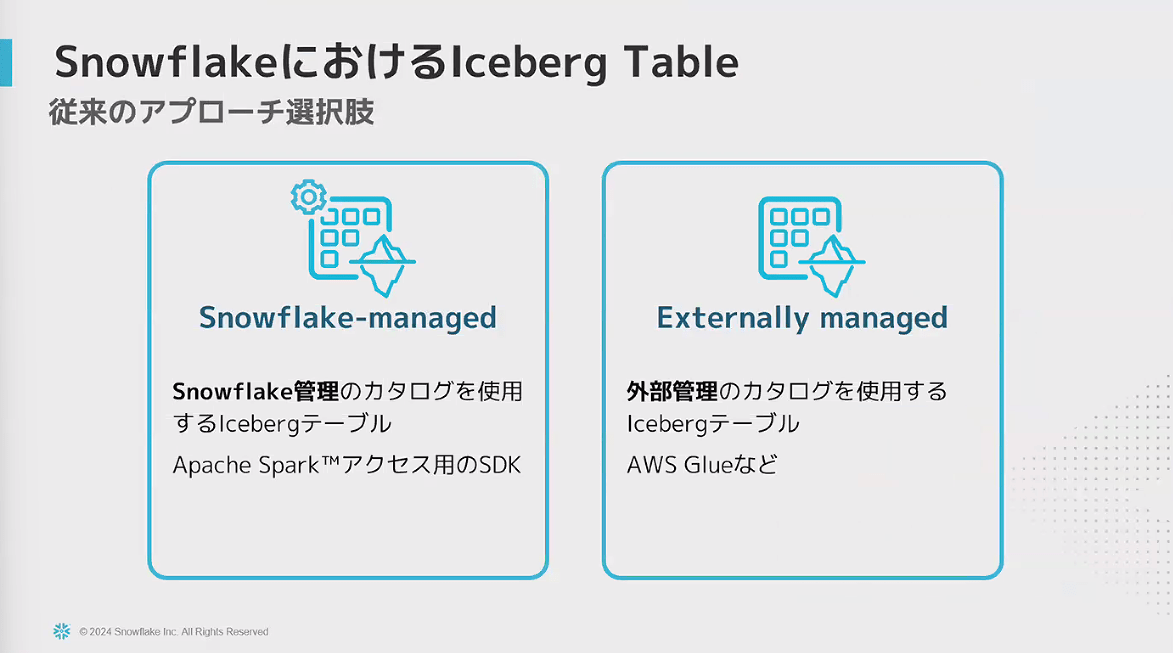
- これまでのIceberg Table
- Apache Polaris
- 今までのカタログは、クエリエンジンとカタログが密に連携していて、クエリエンジンやカタログが固定化されてしまう所があった
- それを解決するためのツールとして、Snowflakeが旗振り役となって開発したのがApache Polaris


- Polaris Catalog(Apache Polaris)の特徴
- ロールレベルのアクセス制御で、各クエリエンジンからアクセスできるテーブルを制御できる

- Snowflake Open Catalog
- Apache Polarisのマネージドサービス

Apache Icebergのデータパイプラインへの組み込み
- SnowflakeとApache Icebergで出来ること

- 効率的なオンボーディング
- CTASでIcebergテーブルを作ることができる
- 既存のparquetのデータセットを用いて、Iceberg化することもできる

- Apache Icebergテーブルへのデータロード

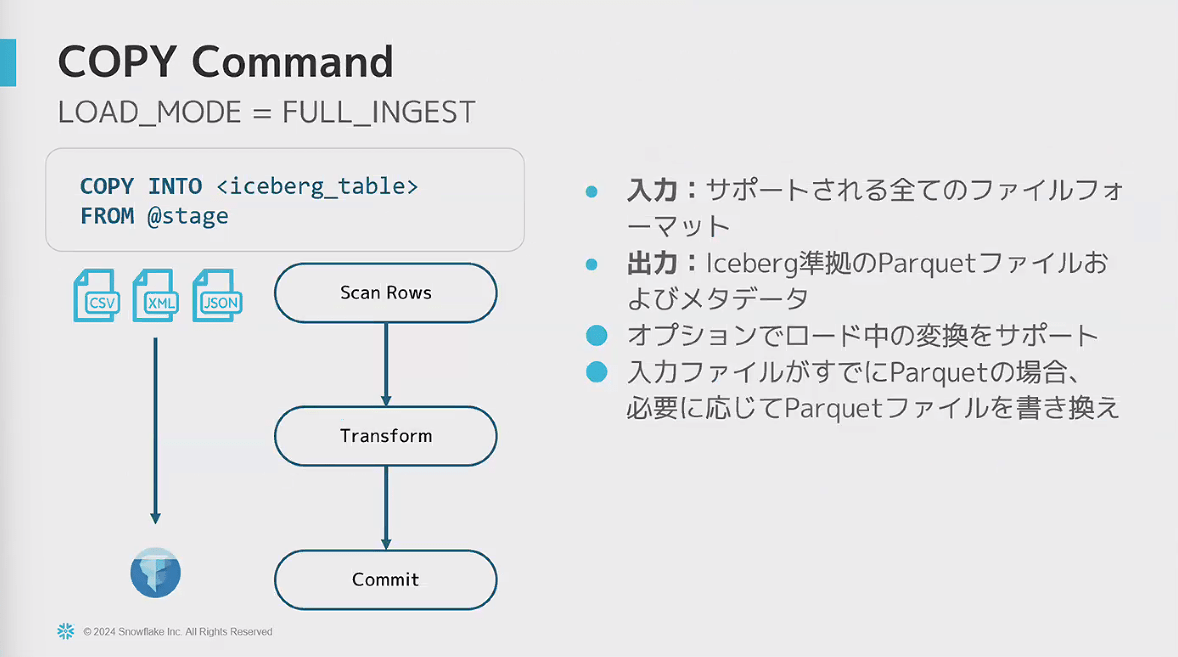
- COPYコマンドでロードする際は、LOAD_MODEオプションで動作を制御可能
- FULL_INGEST:ファイルを再作成する形式
- ADD_FILES_COPY:既存のparquetファイルをコピーして、メタデータだけを新規作成する形式
- 入力のparquetファイルが推奨ファイルに従っている時に特に有効
- ADD_FILES_REFERENCE ※現在開発中
- 既存のParquetファイルのコピーも行わずに、メタデータを作成するだけ


- Snowpipe Streaming
- すでにIcebergへの対応は一般提供
- 注意点として、Ingest SDKの設定値を適用することが必要

- ダイナミックテーブルのサポート ※現在開発中

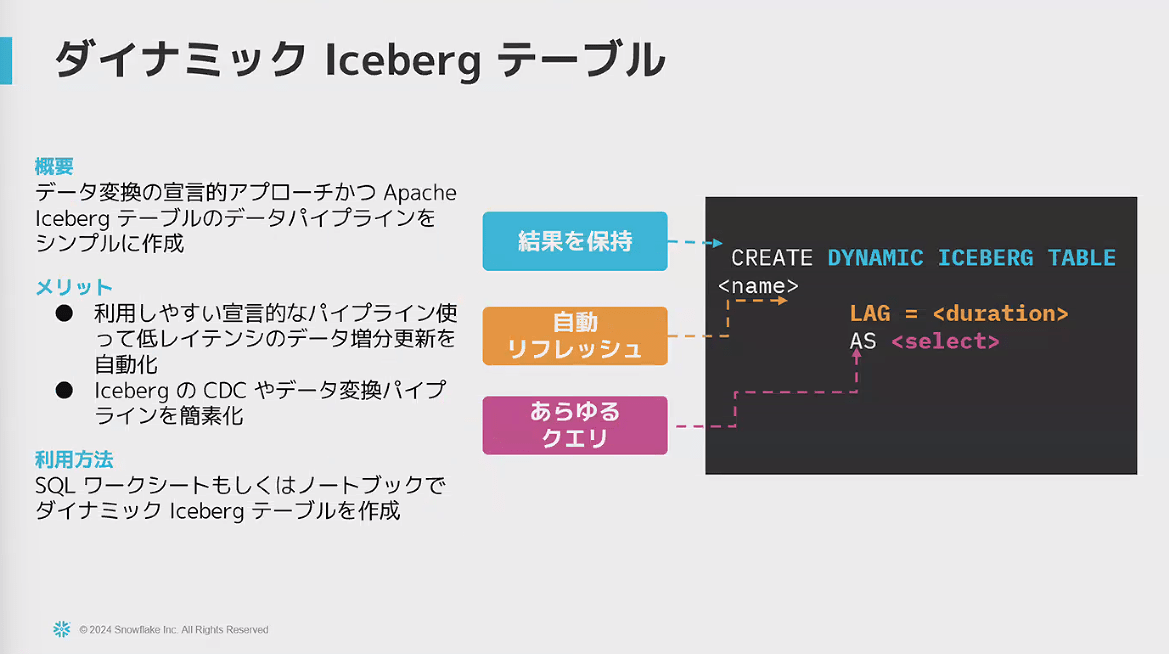
- Icebergテーブルのトランスフォーメーションに関するロードマップ


デモ
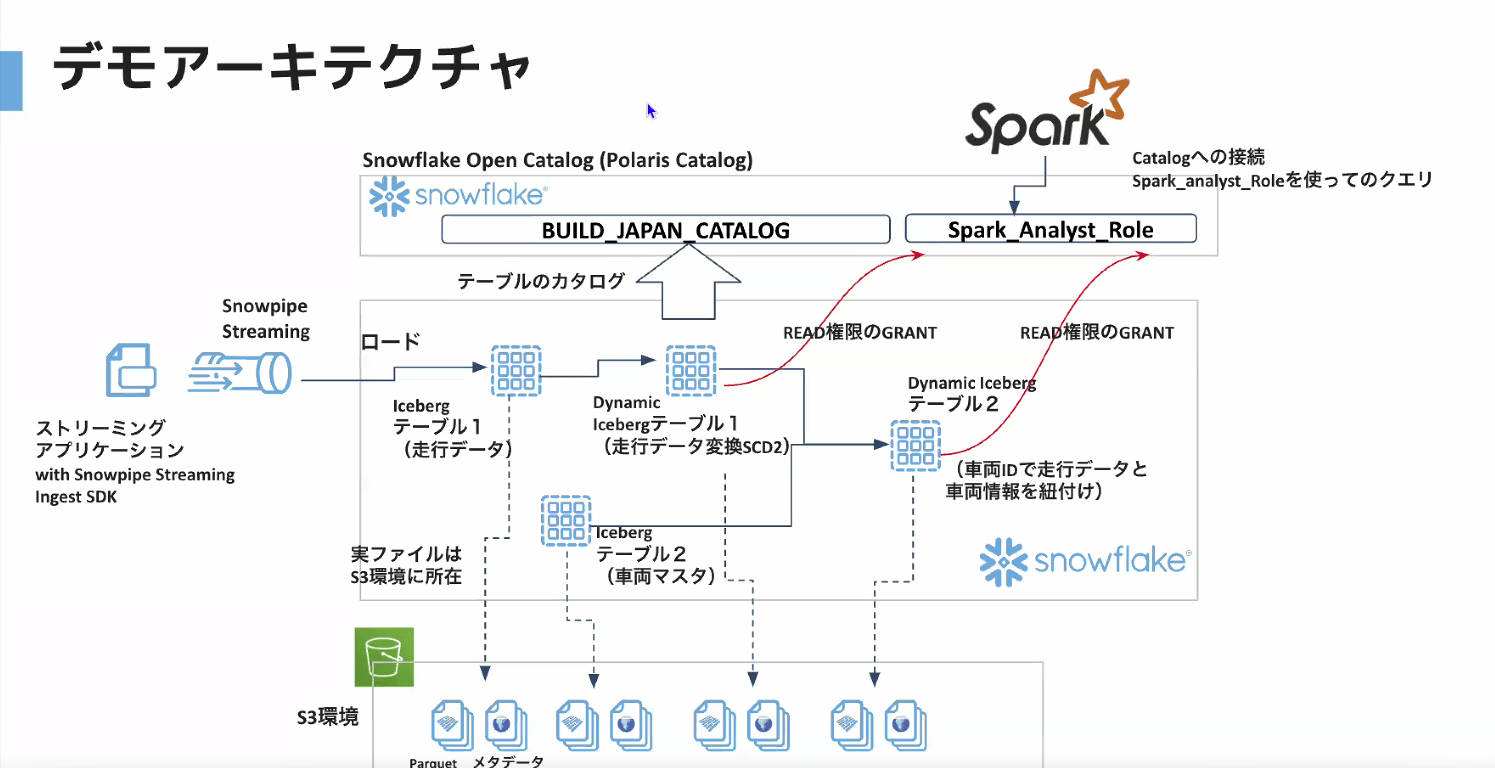
- Snowflake Open Catalogでカタログを作り、Snowflake内でIcebergテーブルを定義していく。加工時はDynamic Icebergテーブルを用いる
- データの抽出はSnowpipe Streaming Ingest SDKを用いたアプリケーションで行い、Icebergテーブルにロードしていく
- 最終的に、Snowflake Open Catalogで作成したロールを用いて、Sparkからアクセスする
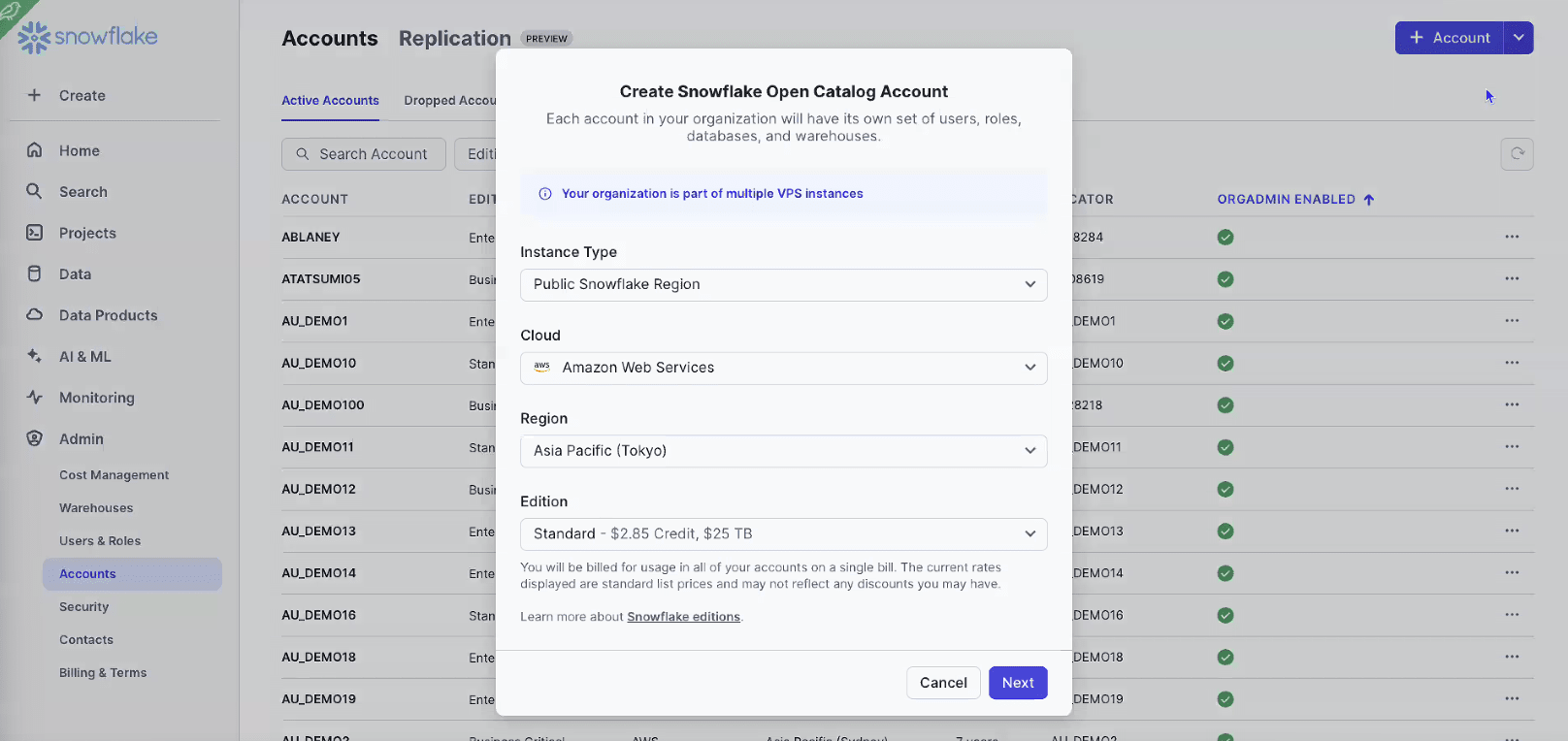
- Snowflake Open Catalogのアカウントの作成
- Snowflake Open Catalogのアカウントで、Connectionsを作成
- Connectionで使用するロール(Principal Role)として、Spark Analyst Roleを定義
※スクリーンショット撮り漏れました…
- Snowflake Open Catalogのアカウントで、カタログを作成
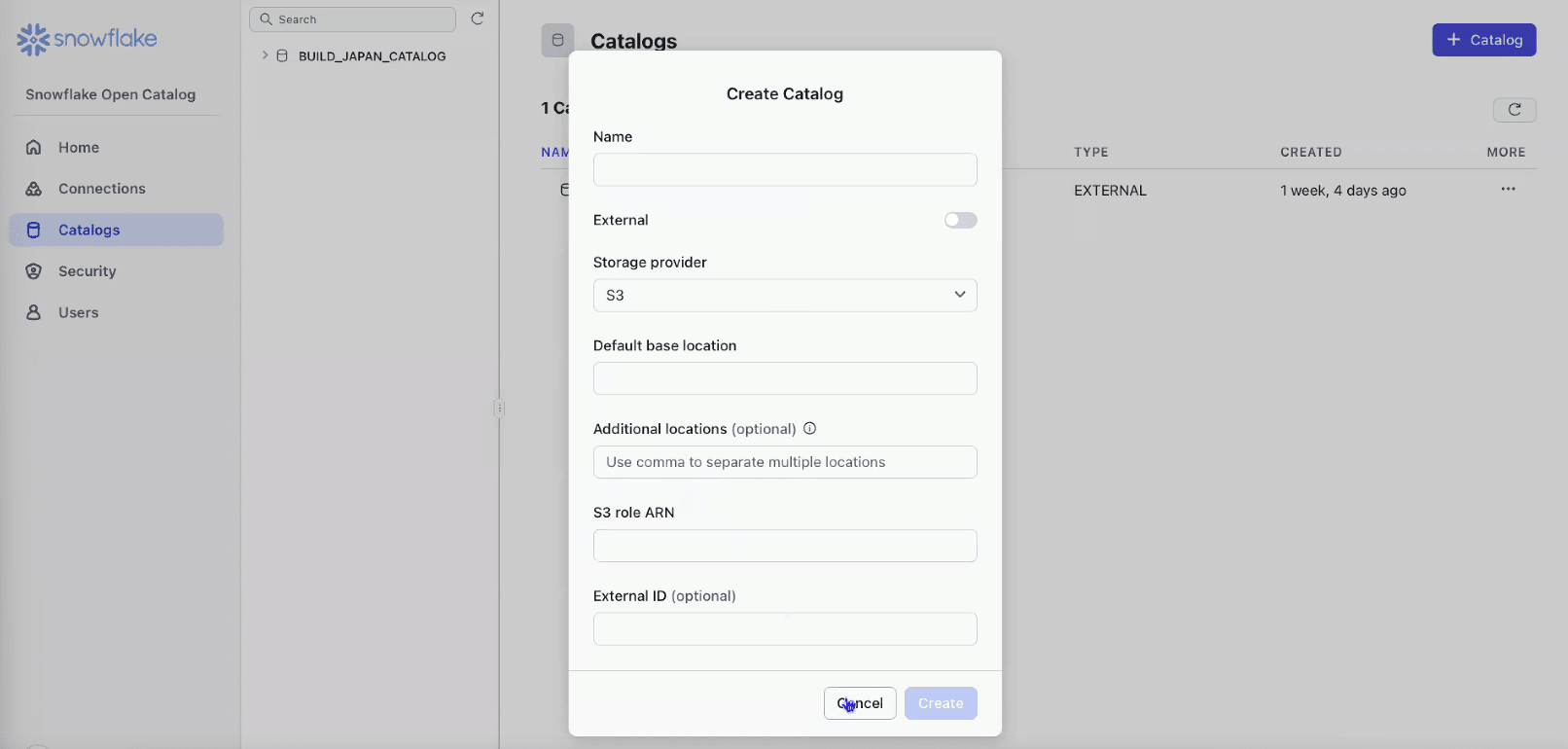
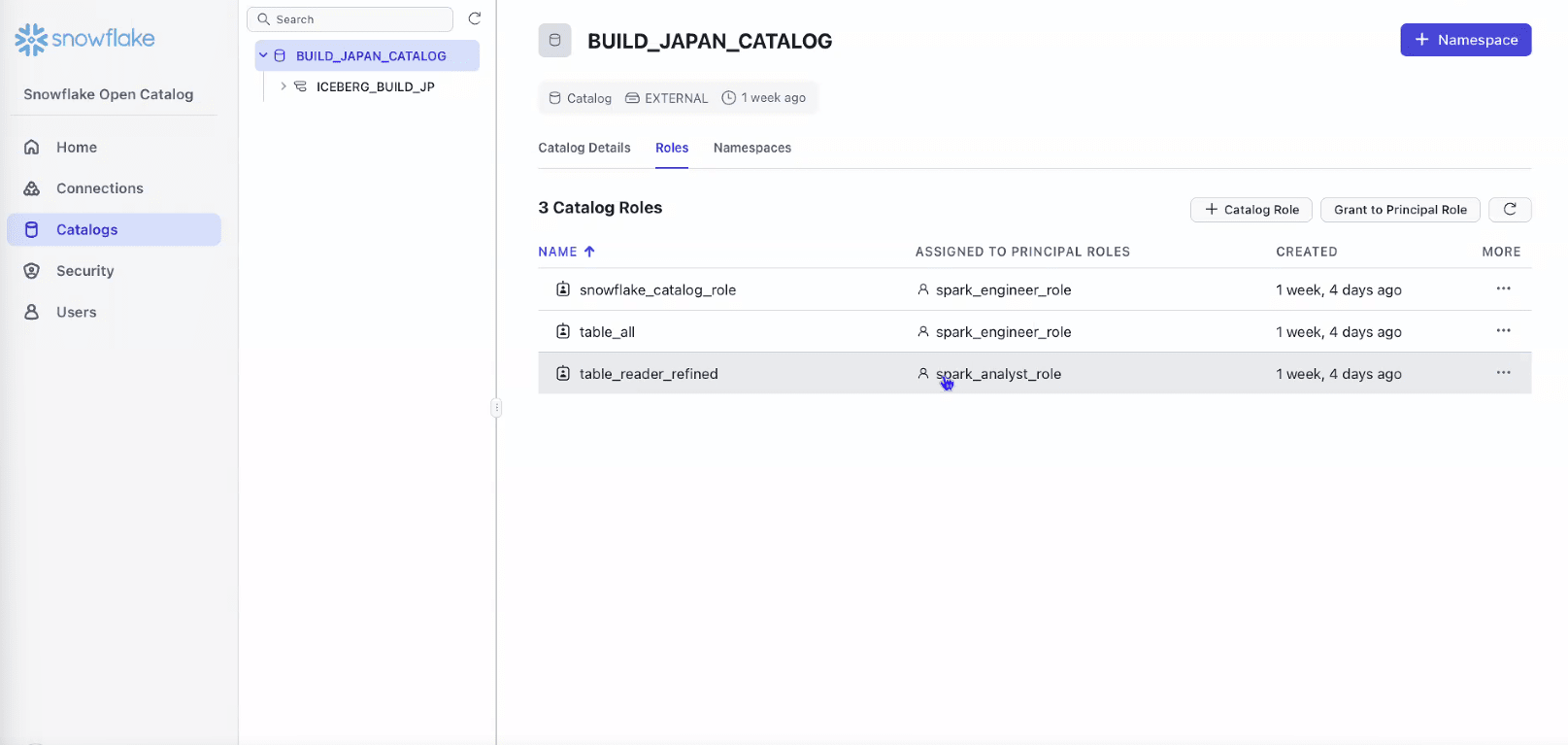
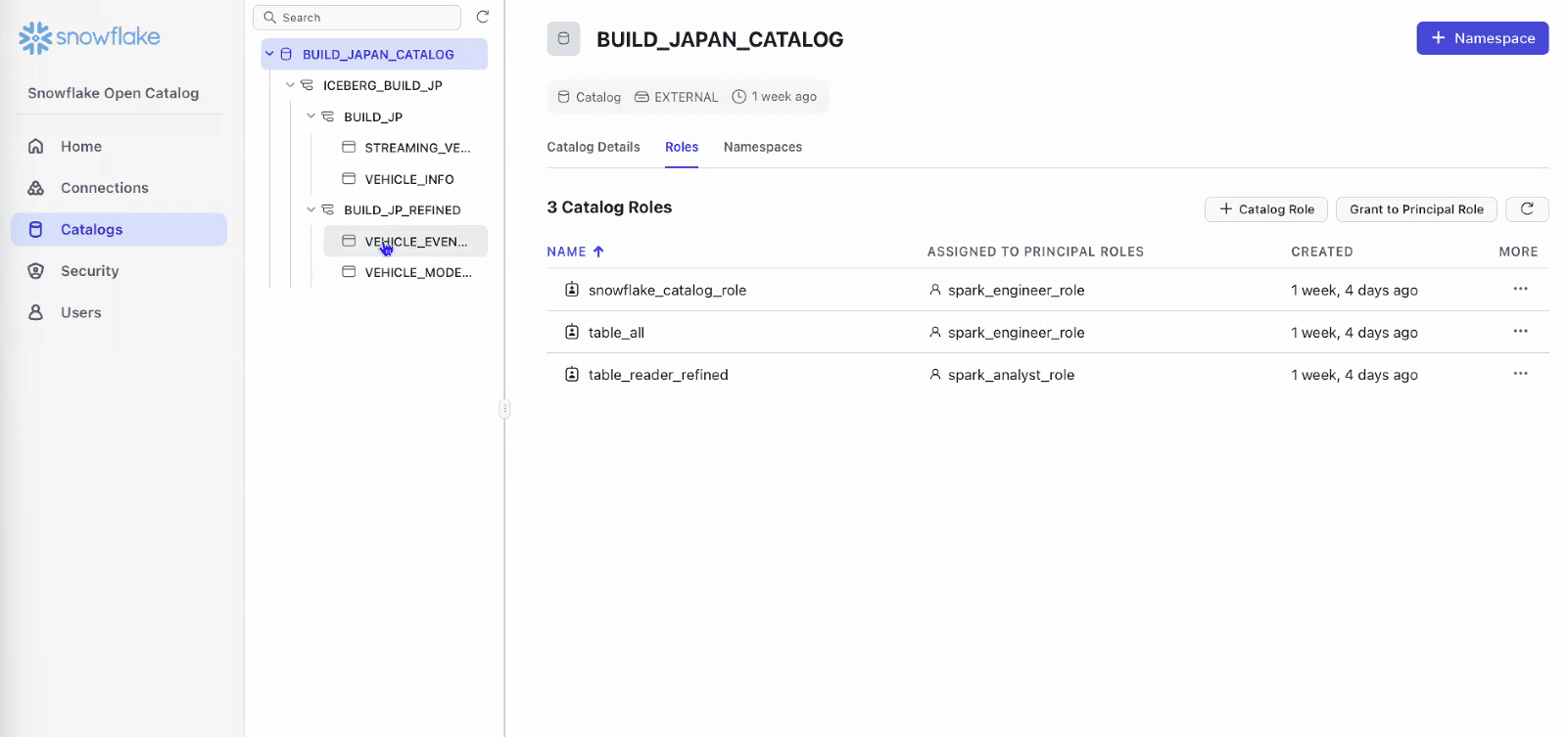
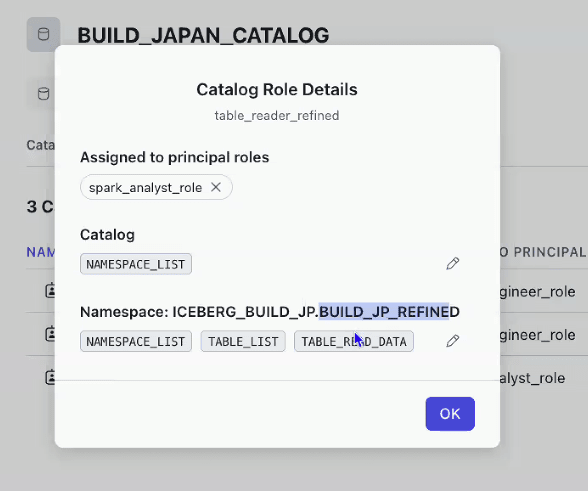
- Catalog Role
- 各テーブルへのアクセス権を付与
- Catalog RoleはPrincipal Roleに付与して利用
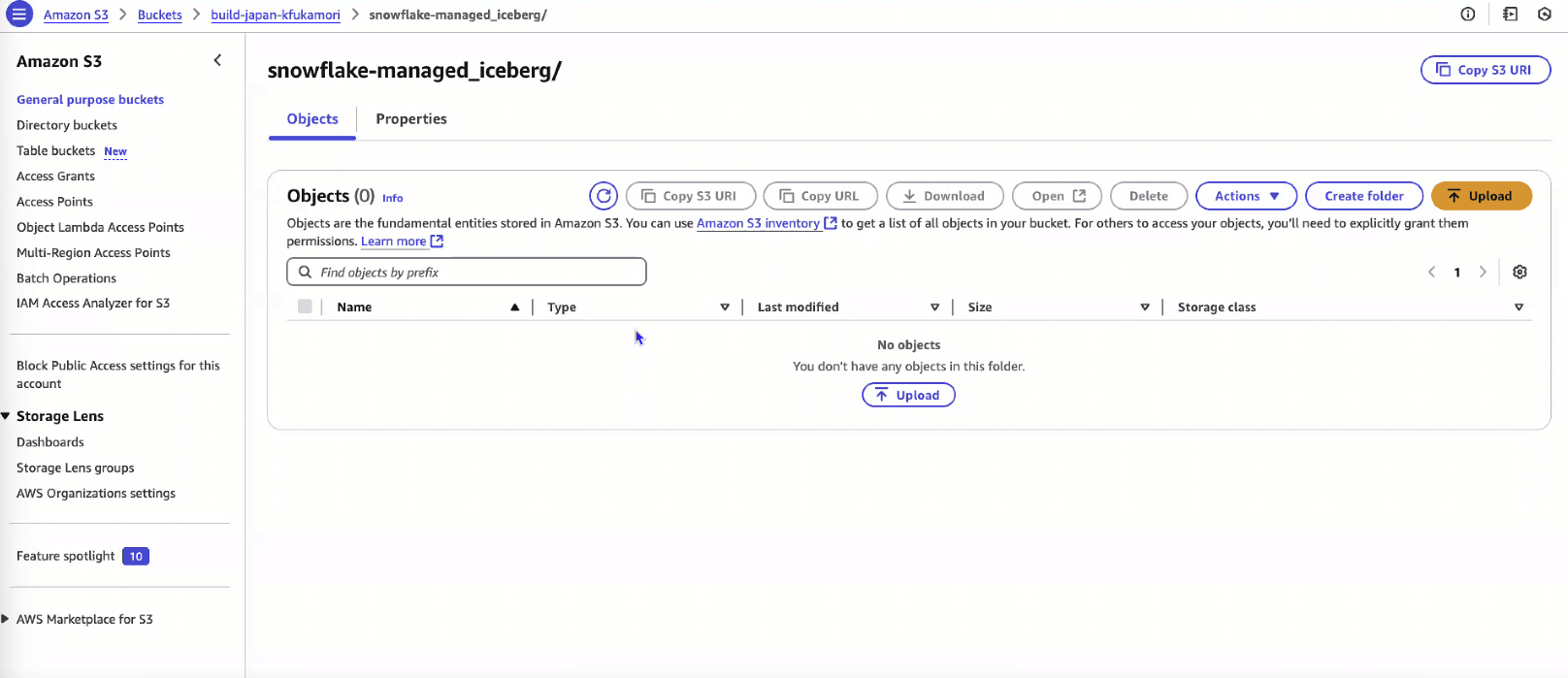
- ロード前のS3の状態(何もデータが存在しない)
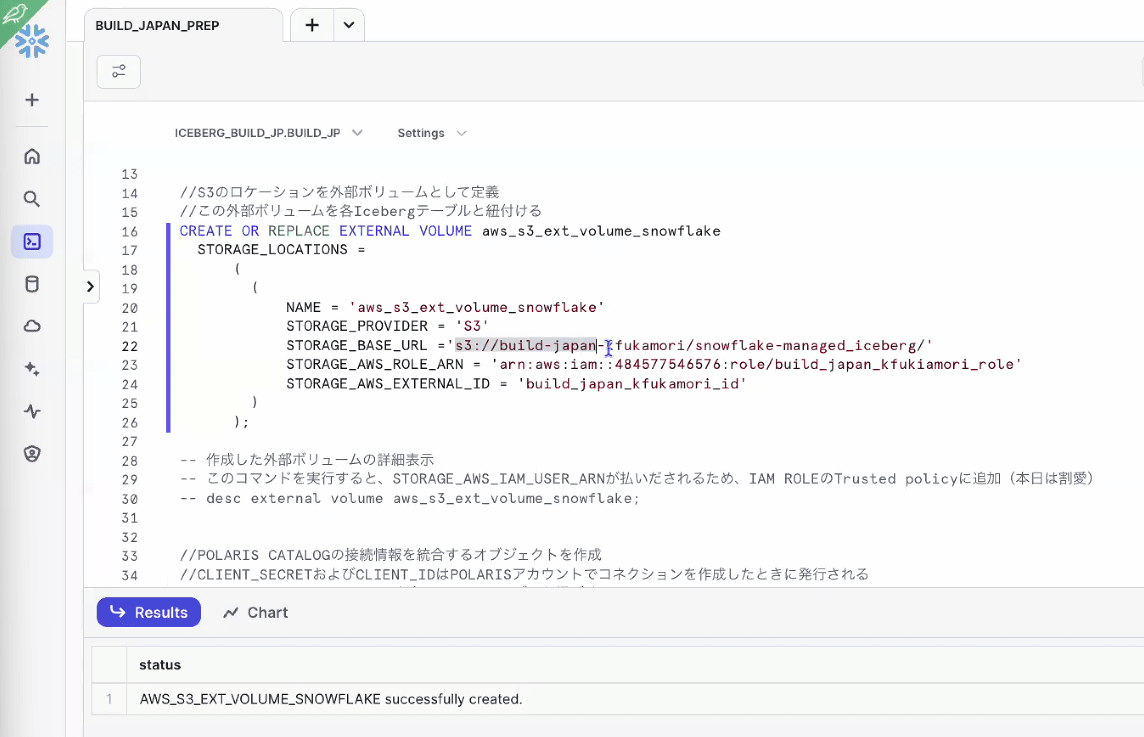
- External Volumeの定義
- S3とつなげる認証情報の定義
- Catalog Integrationの定義
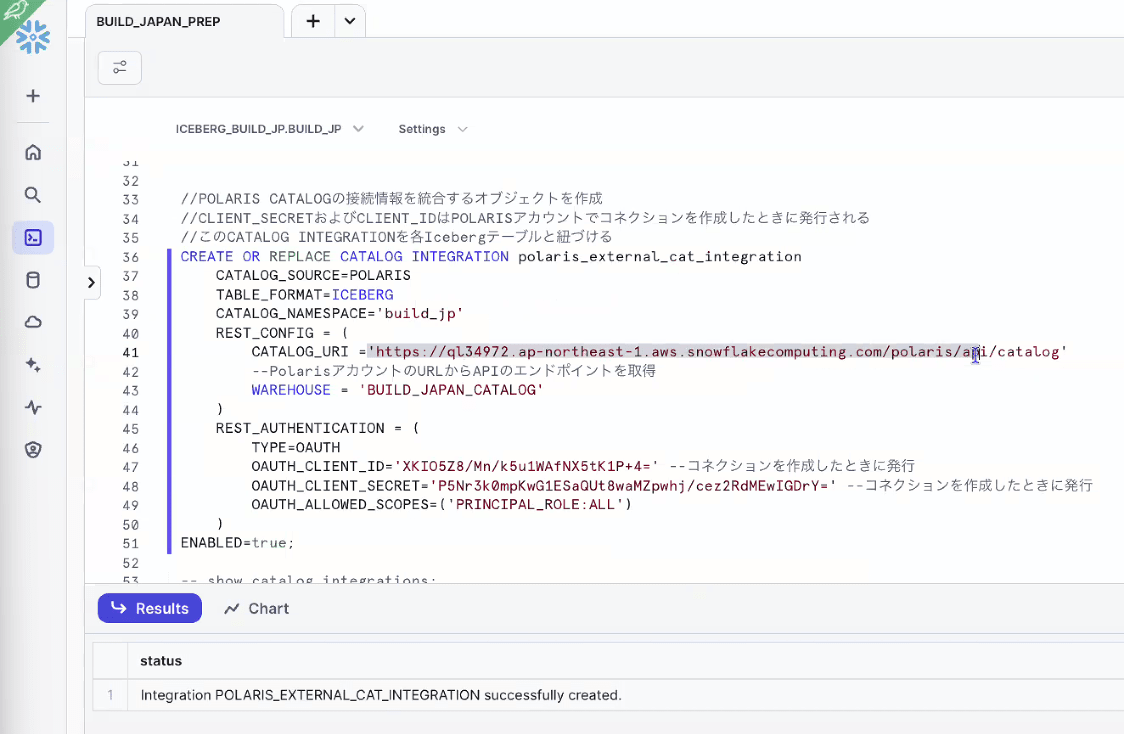
- Icebergテーブルの作成
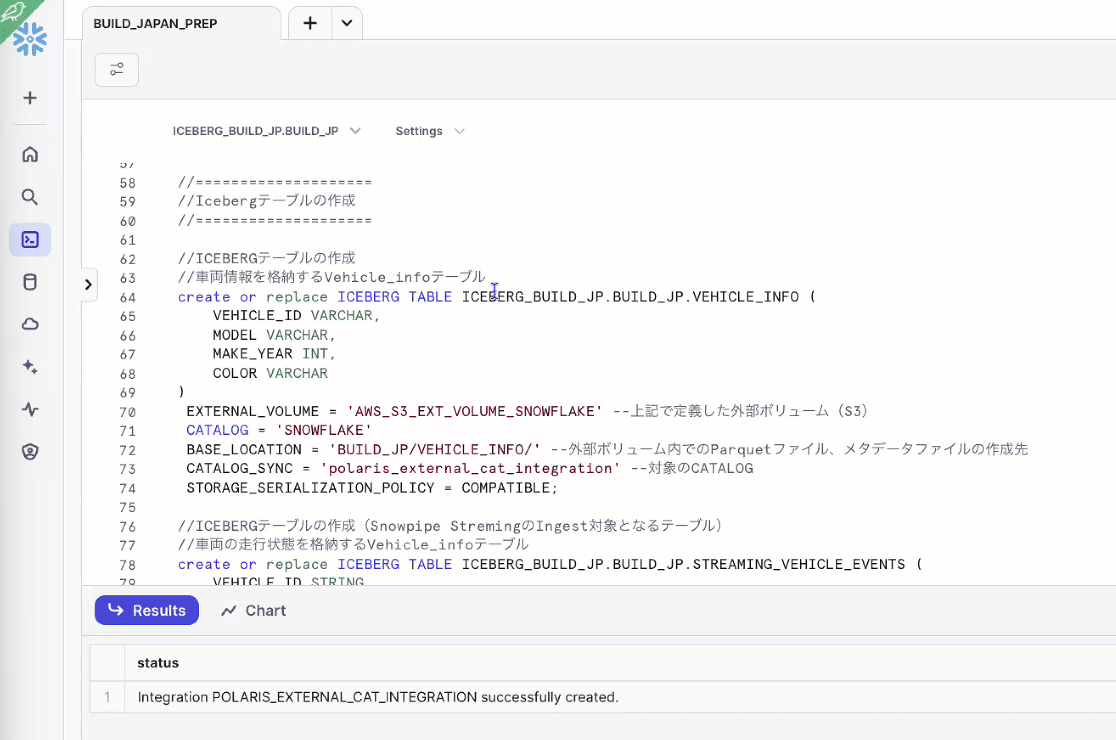
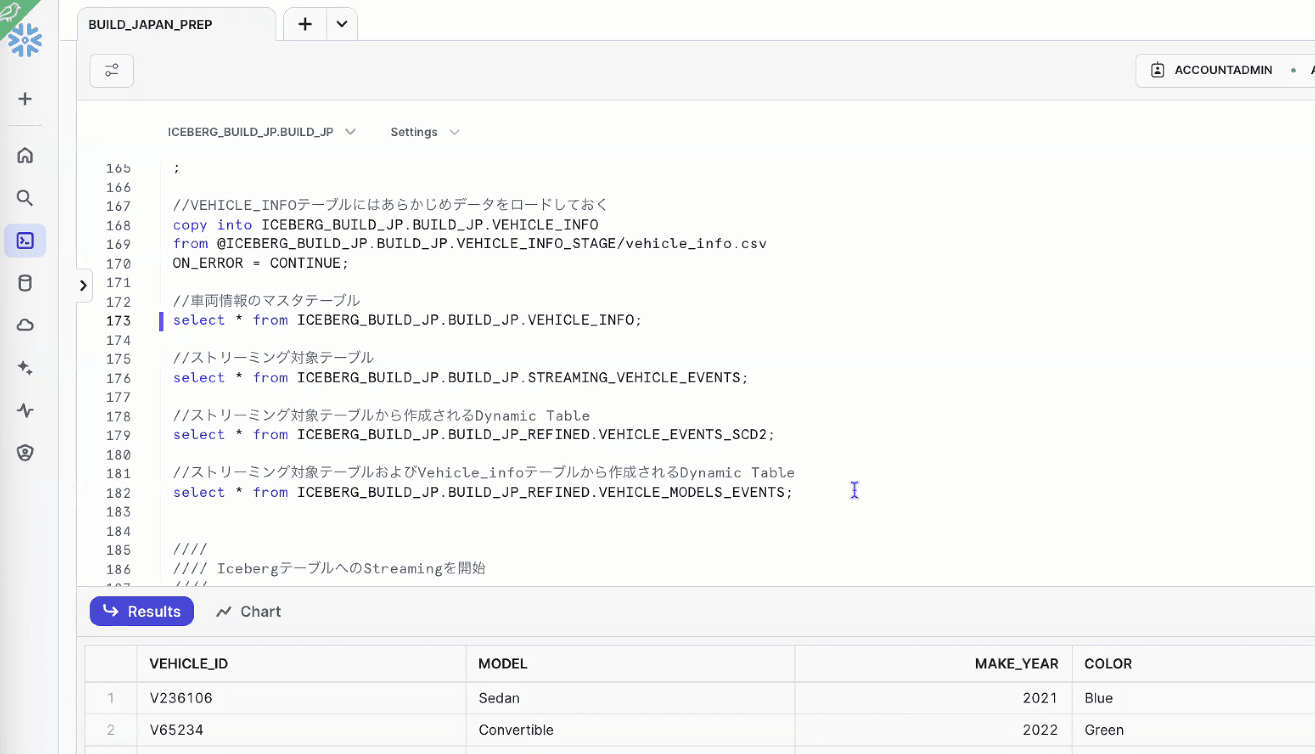
- ストリーミング対象となるテーブル、Dynamic Icebergテーブルを作成
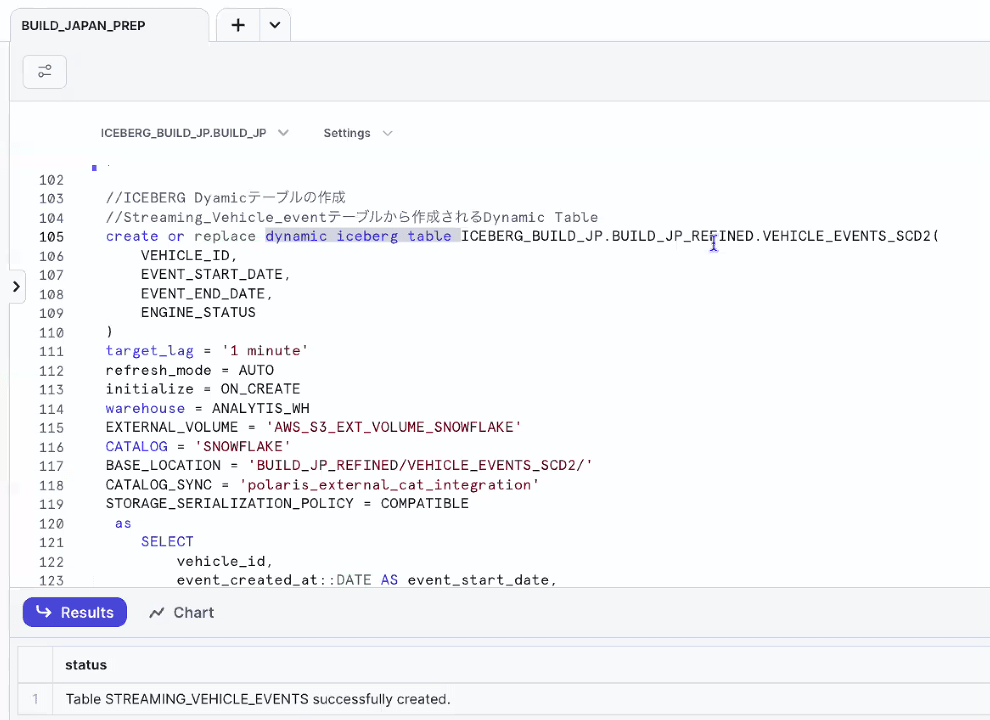
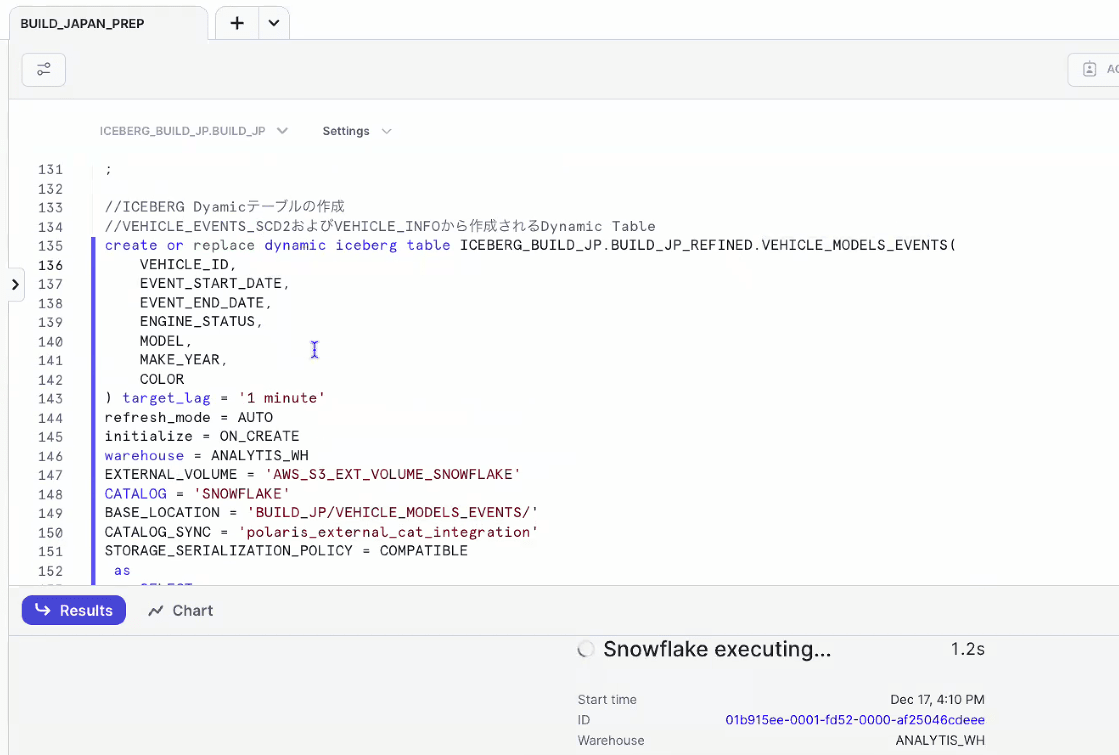
- ストリーミング開始前に、データをロードして確認(Dynamic Icebergテーブルはまだ空っぽ)
- ストリーミングを開始
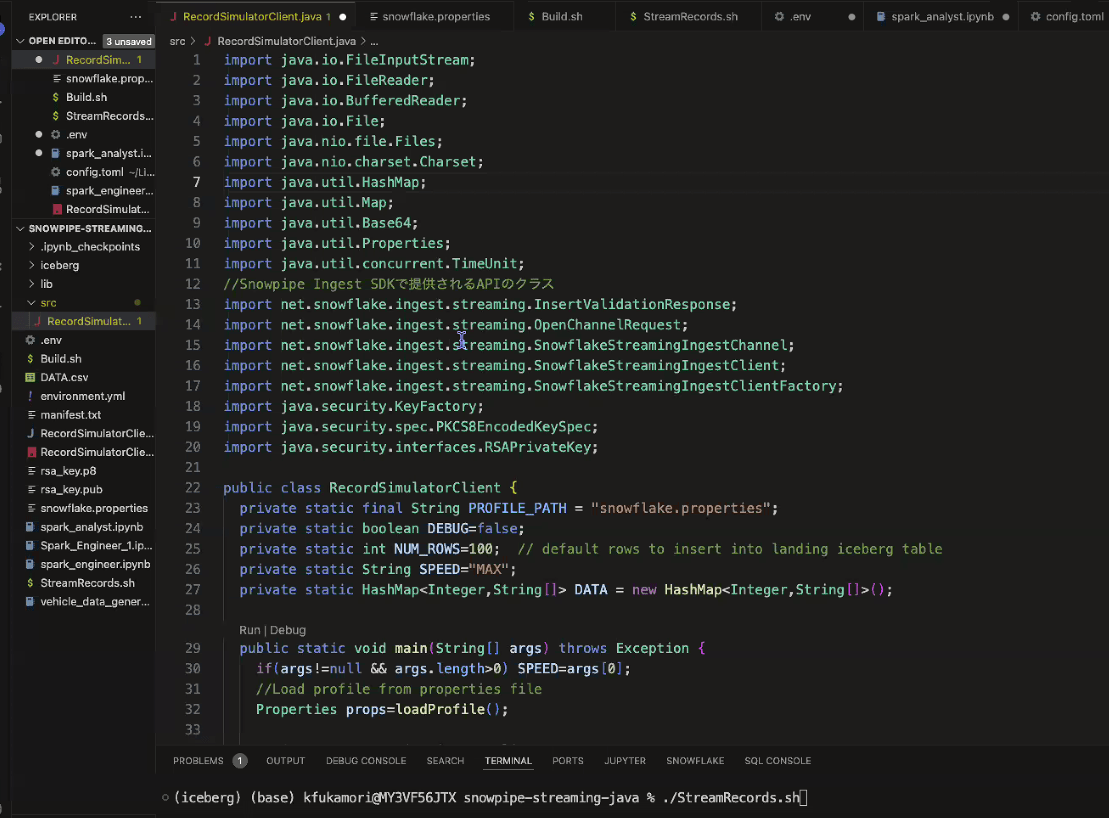
- Ingest SDKで提供されるAPIのクラスを用いて、データを抽出してIcebergテーブルにストリーミングしていく
- Icebergテーブル用の設定値も忘れずに
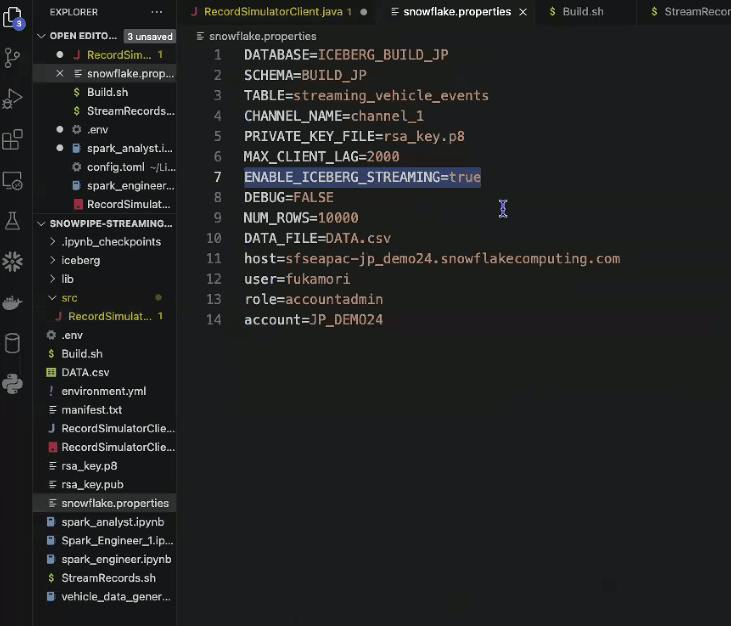
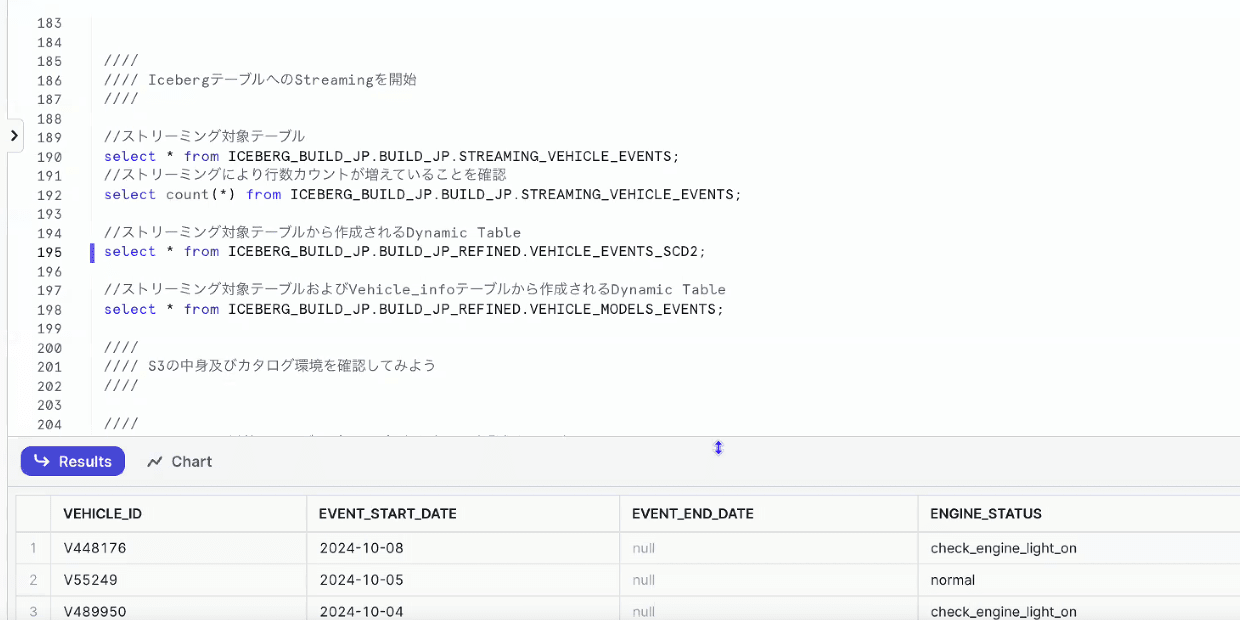
- ストリーミング開始されたので、データがIcebergテーブルにロードされていく
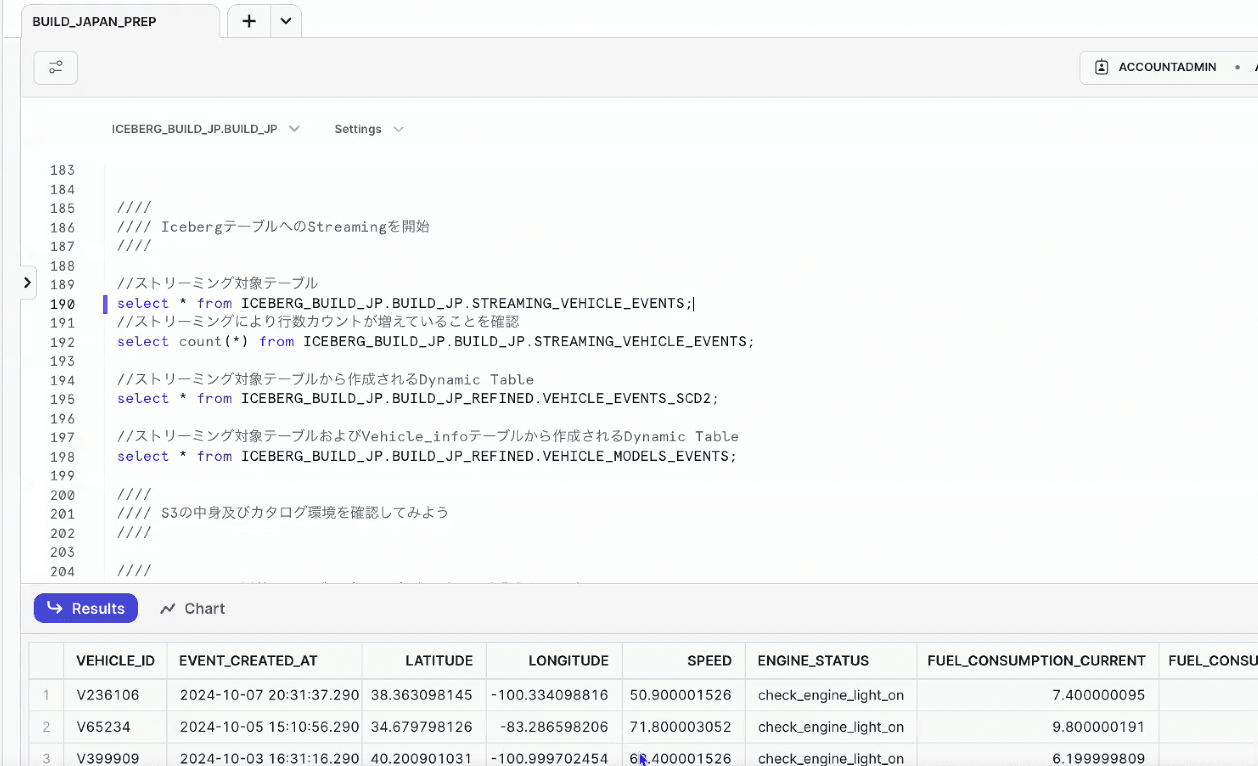
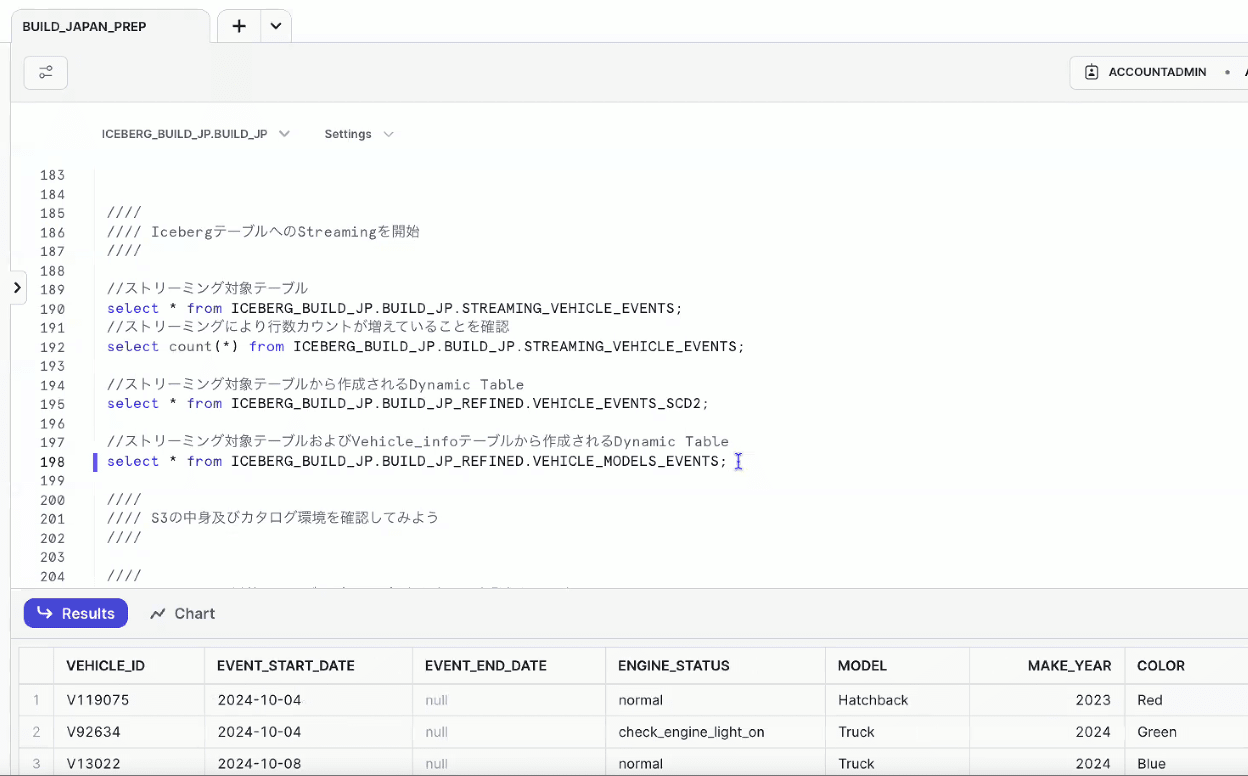
- Iceberg Dynamicテーブルを見ると、加工されたデータが入っていることがわかる
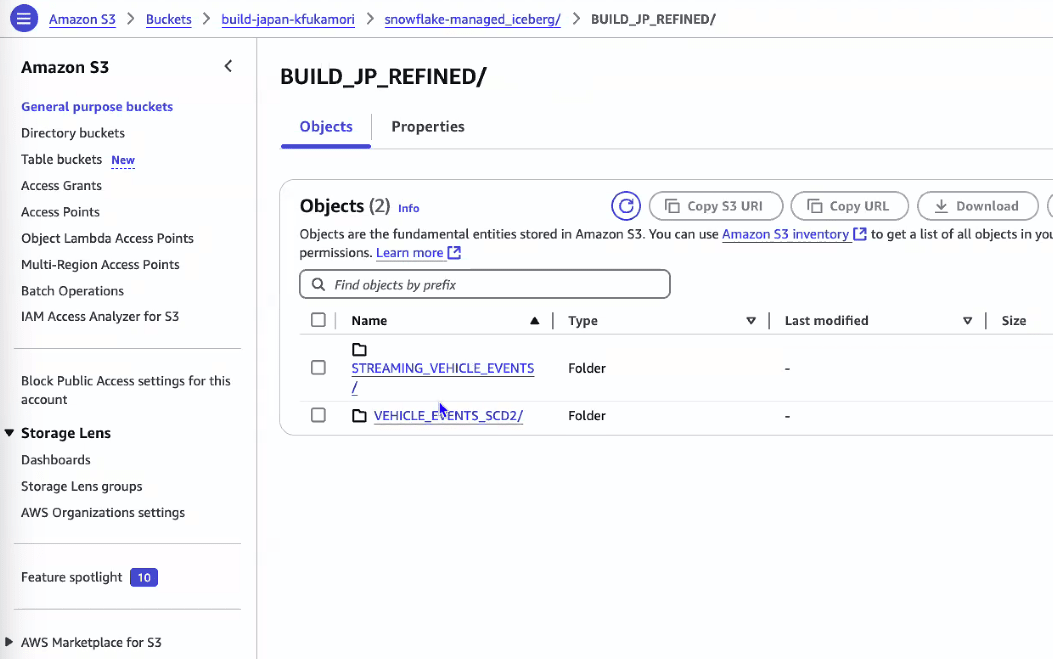
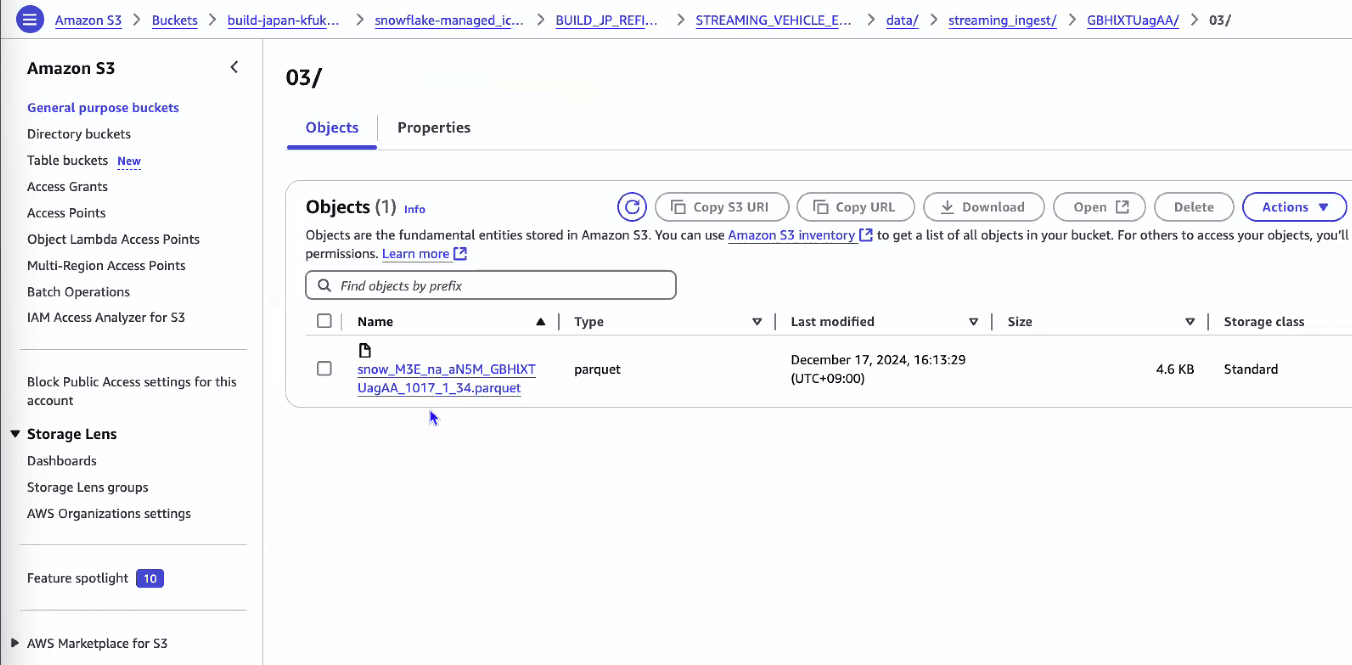
- S3を見ると、parquetファイルが追加され、メタデータも追加されている
- テーブルとしてもちゃんと認識されている
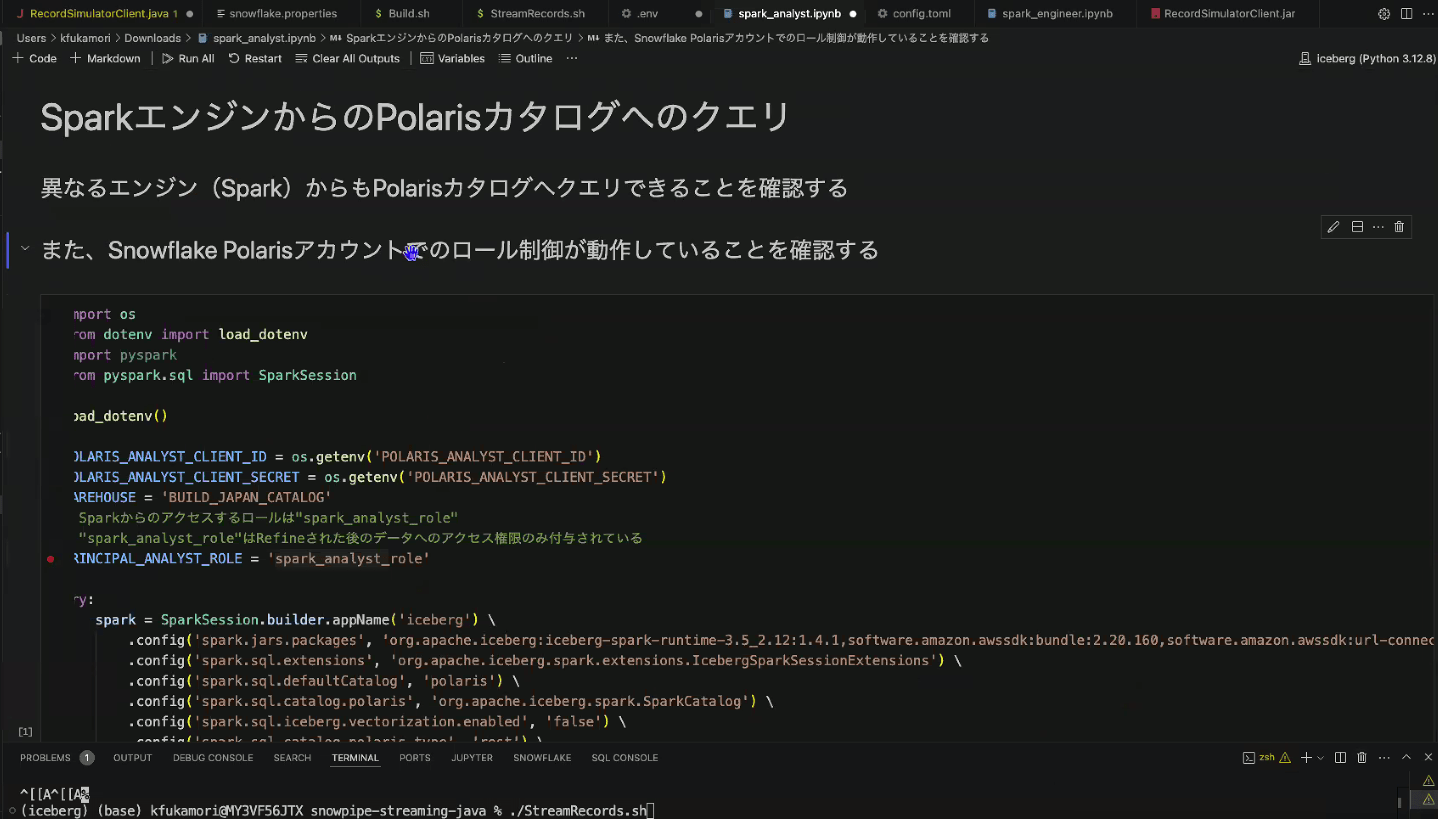
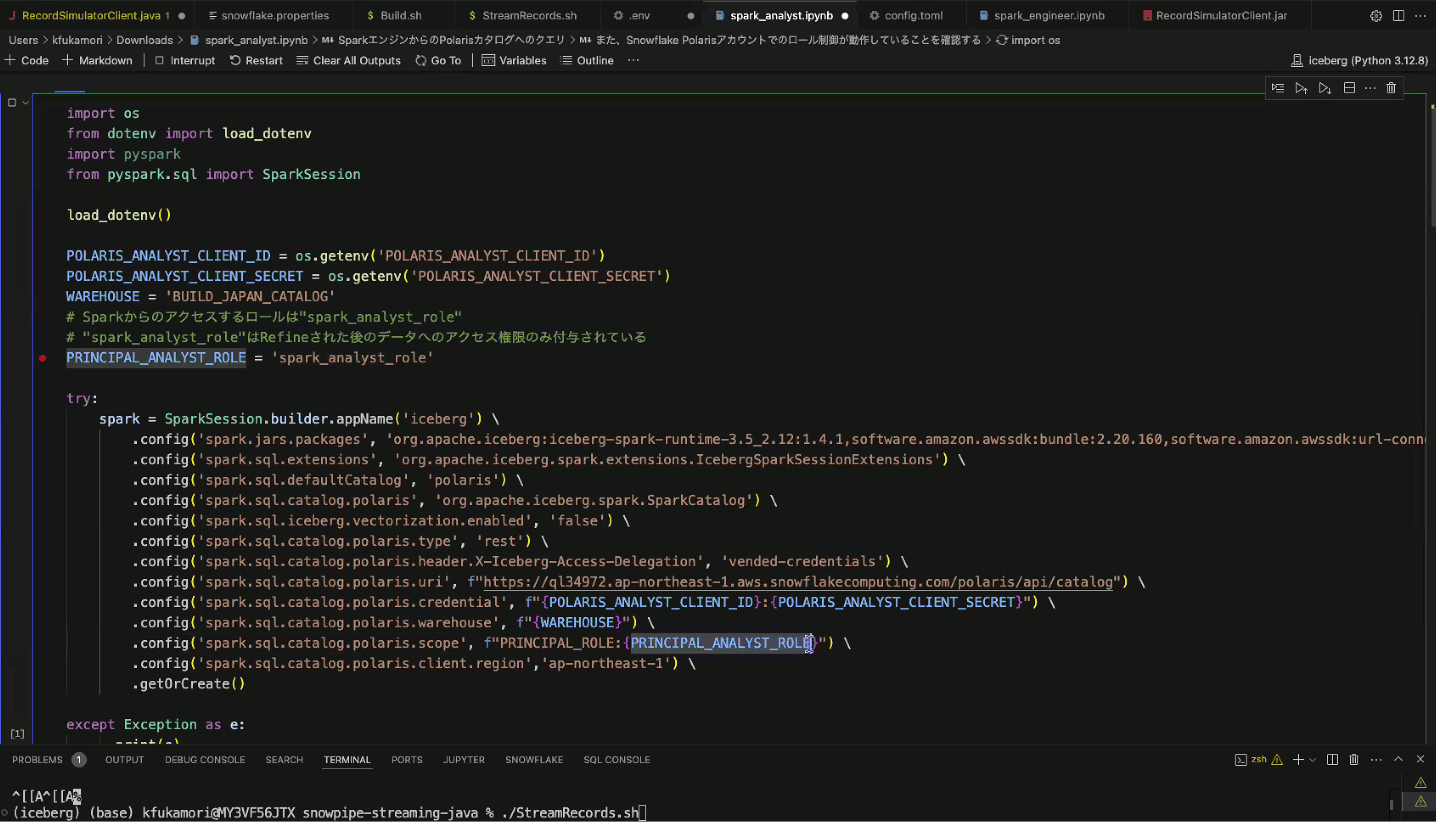
- Sparkから、Icebergテーブルにアクセス
- アクセス権が付与されていないnamespaceへのクエリは、エラーとなる
※エラーのスクリーンショット撮り漏れました…
- アクセス権がある場合は、Sparkからクエリできる
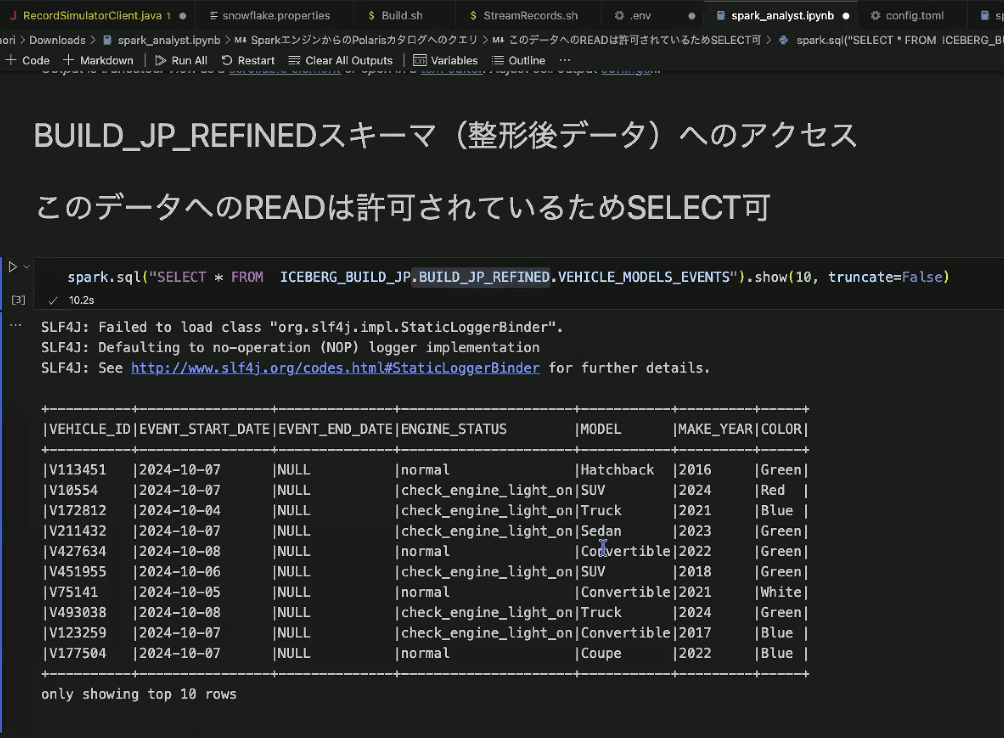
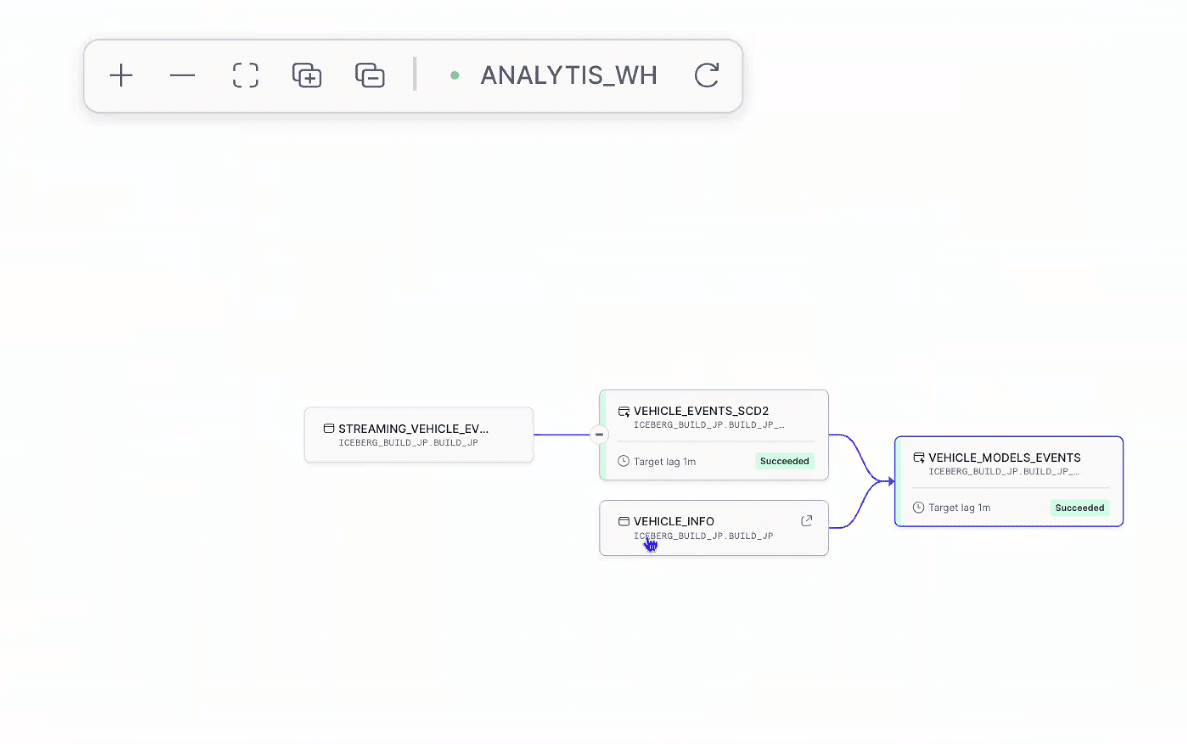
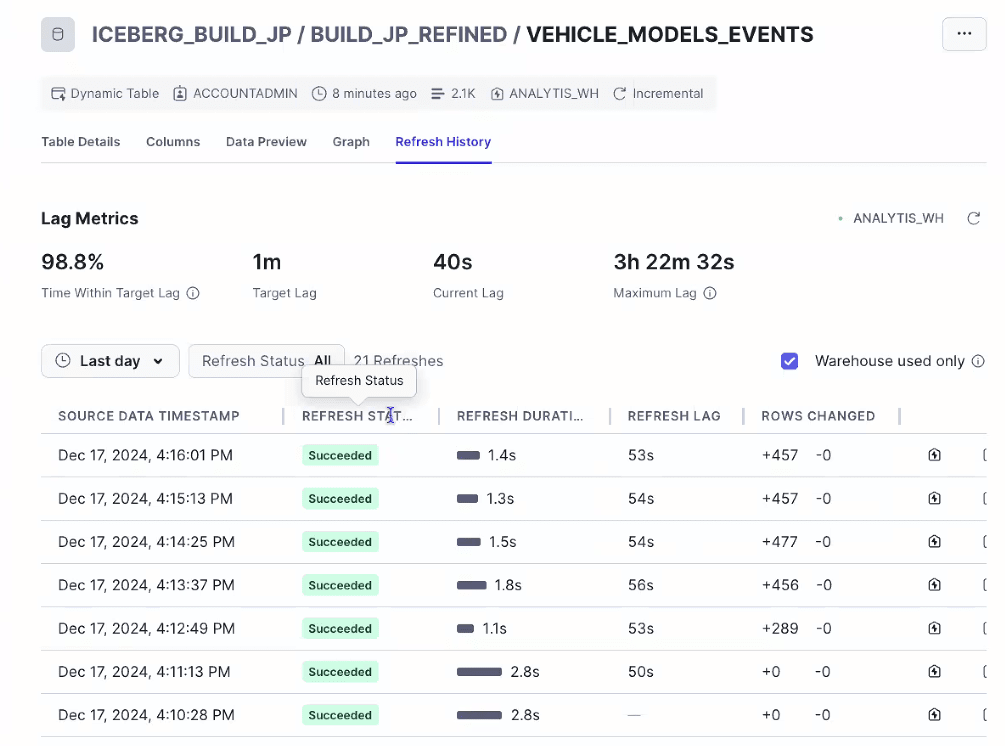
- おまけ:Dynamicテーブルを作成すると、どのテーブルから作られているかのリネージ、更新処理の実行履歴も確認可能
その他のデータエンジニアリング機能アップデート
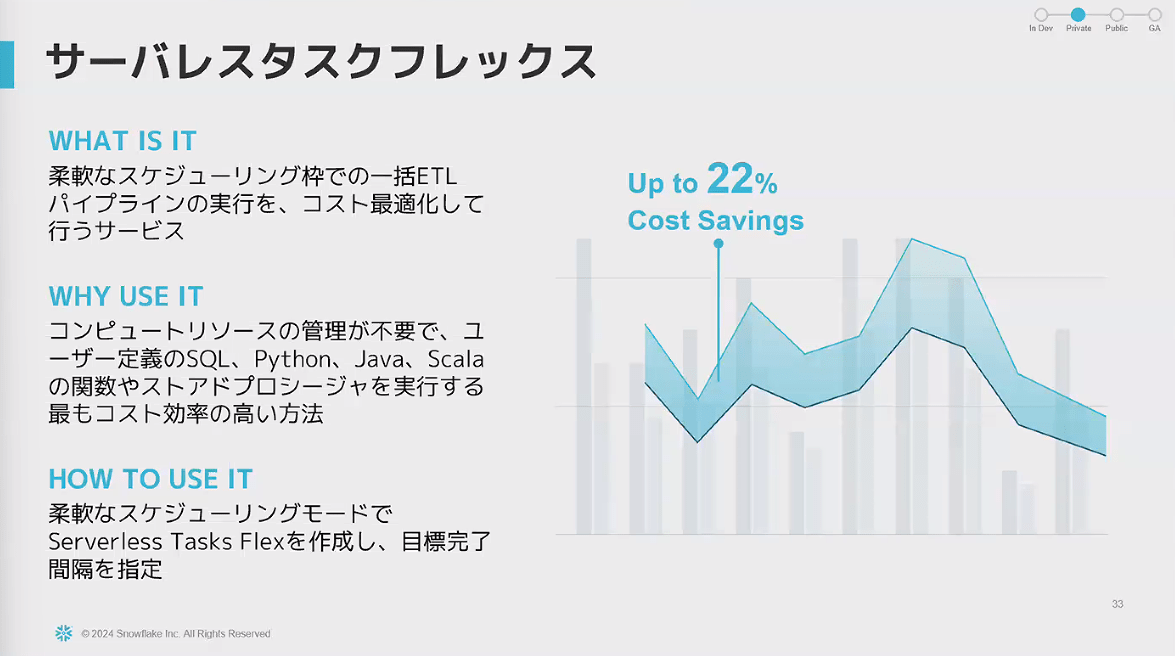
- サーバレスタスクフレックス
- 実行完了までの時間枠の幅をもたせ、コストを最適化出来る機能
- Snowflake Pandas API
- 利用者が多いPandasと同じような記法でコードを書き、実行時はSnowflakeのSQLにプッシュダウンされる


まとめ
- IcebergをSnowflakeのデータパイプラインでどのように使えるかを説明してきた
- 本セッションをきっかけにIcebergを使うきっかけとなると嬉しい